DataScience Training












Keywords
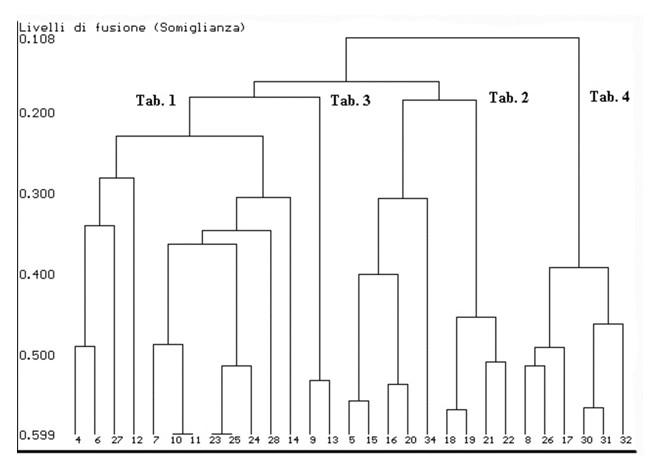
Statistische Einheiten, Cluster, Intra-Cluster, Inter-Cluster, Dissimilaritätsindex, Merge-Distanz, Dendogramm.
Objectives/goals:Ziel dieses Moduls ist es, die Technik der Clusteranalyse einzuführen und zu erklären.
Am Ende dieses Moduls werden Sie in der Lage sein:
- Die Logik der Clusteranalyse zu verstehen
- Die Anforderungen zu kennen
- Eine Clusteranalyse durchzuführen
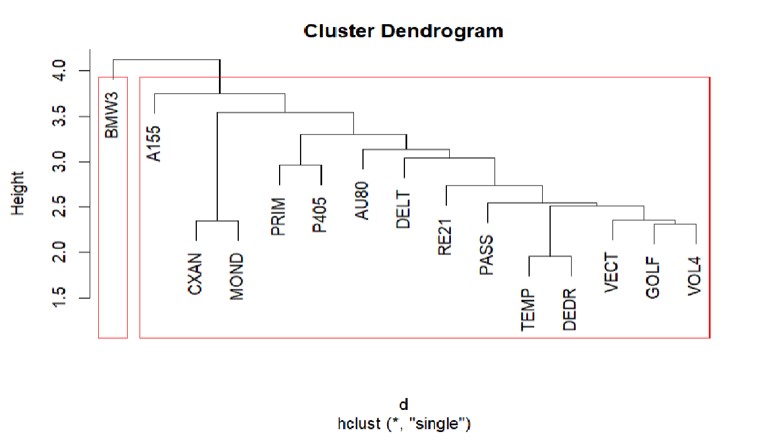
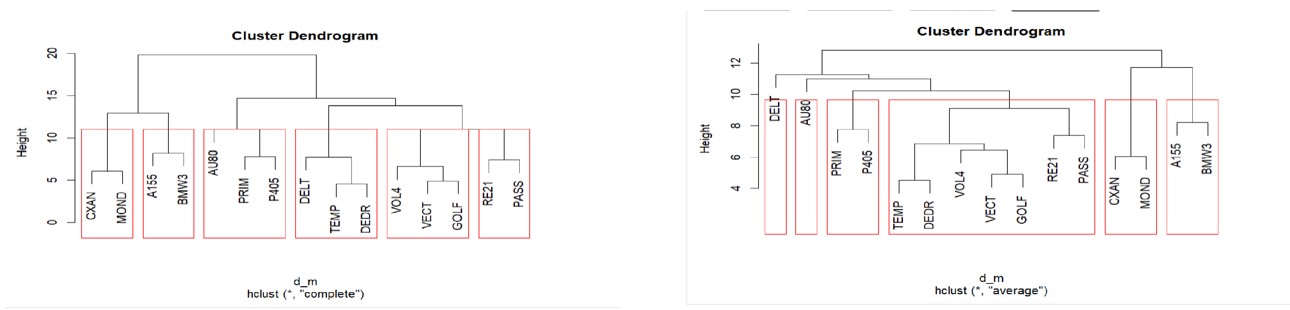
In diesem Modul lernen wir die mehrdimensionale Analysetechnik der Clusteranalyse kennen, die auch automatische Gruppenanalyse genannt wird.
Clusteranalysen dienen dazu, statistische Einheiten, die gemeinsame Merkmale aufweisen, zu gruppieren und sie nicht a priori definierten Kategorien zuzuordnen. Die gebildeten Gruppen müssen innerhalb (Intra-Cluster) möglichst homogen und außerhalb (Inter-Cluster) heterogen sein.
Die Anwendungsmöglichkeiten dieser Art von Analyse sind vielfältig: Clusteranalysen werden z.B. in der Informatik, Medizin, Biologie, oder im Marketing genutzt.
Im letzten Teil des Moduls lernen wir, wie wir die Software R für Clusteranalysen einsetzen können.
Related training material






