|
Text Mining
Introduction
What is Text Mining? Click to read 
•Text mining is a confluence of natural language processing, data mining, machine learning, and statistics used to mine knowledge from unstructured text.
•Generally speaking, text mining can be classified into two types:
ØThe user’s questions are very clear and specific, but they do not know the answer to the questions.
ØThe user only knows the general aim but does not have specific and definite questions.
Text Mining Challenges Click to read
•Natural language text is unstructured.
•Most data mining methods handle structured or semi-structured data=> the analysis and modeling of unstructured natural language text is challenging.
•Text data mining is de facto an integrated technology of natural language processing, pattern classification, and machine learning.
•The theoretical system of natural language processing has not yet been fully established.
•The main difficulties confronted in text mining are generated by:
ØThe occurrence of noise or ill-formed expressions,
ØAmbiguous expressions in the text,
ØDifficult collection and annotation of samples to nurture machine learning methods,
ØHard to express the purpose and requirements of text mining
Text Mining Processing Flow Click to read
•Text mining performs some general tasks to effectively mine texts, documents, books, comments:
Text mining techniques
Typical text mining techniques Click to read
Text mining is a research field crossing multiple technologies and techniques:
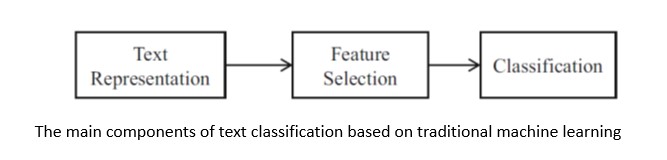
ØText classification methods divide a given text into predefined text types.
ØText clustering techniques divide a given text set into different categories.
ØTopic models = statistical models used to mine the topics and concepts hidden behind words in text.
ØText sentiment analysis (text opinion mining) reveals the subjective information expressed by a text’s author, that is, the author’s viewpoint and attitude. The text is classified based on attitudes expressed in the text or judgments of its positive or negative polarity.
ØTopic detection refers to the mining and screening of text topics (hot topics) reliable for public opinion analysis, social media computing, and personalized information services.
ØInformation Extraction refers to the extraction of factual information such as entities, entity attributes, relationships between entities, and events from unstructured and semistructured natural language text which it forms into structured data output.
ØAutomatic text summarization automatically generates summaries using natural language processing methods.
Techniques for Data Preparation and Transformation Click to read
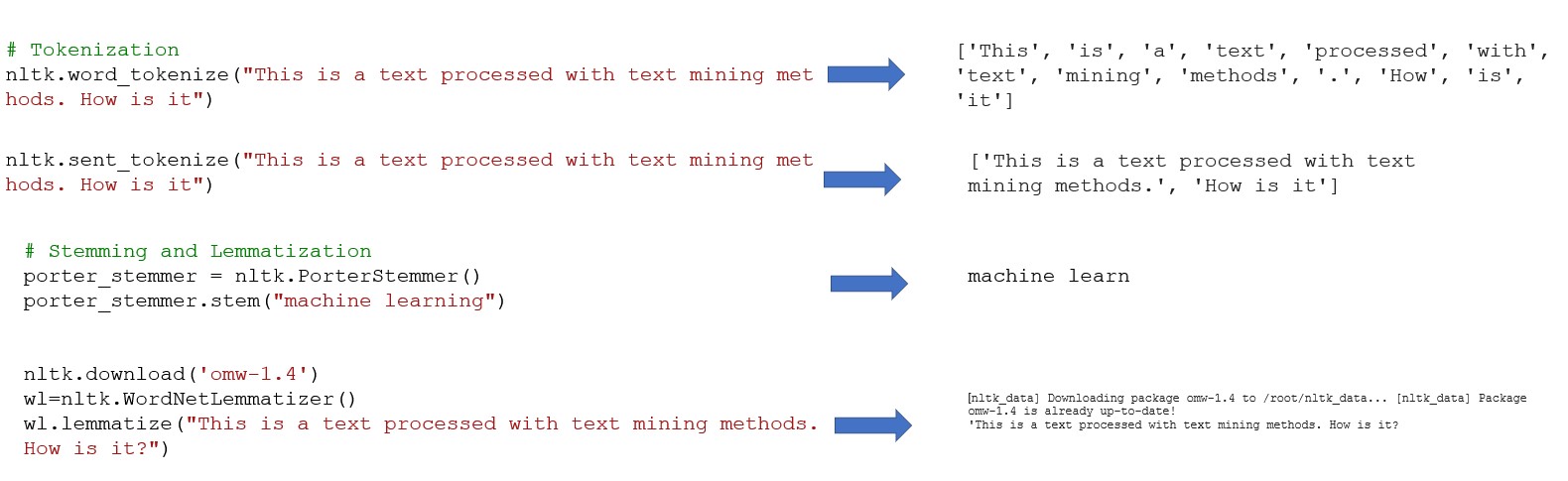
•Tokenization refers to a process of segmenting a given text into lexical units.
•Removing stop words: Stop words mainly refer to functional words, including auxiliary words, prepositions, conjunctions, modal words, and other high frequency words.
•Word form normalization to improve the efficiency of text processing. Word form normalization includes two basic concepts:
ØLemmatization - the restoration of deformed words into original forms, to express complete semantics,
ØStemming - the process of removing affixes to obtain roots.
•Data annotation represent an essential stage of supervised machine learning methods. If the scale of annotated data is larger, the quality is higher, and if the coverage is broader, the performance of the trained model will be better.
Text Representation Click to read
Basics of Text Representation
•Vector Space Model is the simplest text representation method.
•Related basic concepts:
ØText is a sequence of characters with certain granularities, such as phrases, sentences, paragraphs, or a whole document.
ØTerm is the smallest inseparable language unit that can denote characters, words, phrases, etc.
ØTerm weight is the weight assigned to a term according to certain principles, indicating that term’s importance and relevance in the text.
•The vector space model assumes that a text conforms to the following two requirements: (1) each term ti is unique, (2) the terms have no order.
Text Representation
•The goal of deep learning for text representation is to learn low-dimensional dense vectors of text at different granularities through machine learning.
•The bag-of-words model is the most popular text representation method in text data mining tasks such as text classification and sentiment analysis.
•The goal of text representation is to construct a good representation suitable for specific natural language processing tasks:
ØFor the sentiment analysis task, it is necessary to embody more emotional attributes,
ØFor topic detection and tracking tasks, more event description information must be embedded,
Text classification Click to read
Text Classification
•In text classification, a document must be correctly and efficiently represented for classification algorithms.
•The selection of a text representation method depends on the choice of classification algorithm.
Basic Machine Learning Algorithms for Text Classification
•Text classification algorithms:
ØNaive Bayes is a collection of classifiers which works on the principles of the Bayes’ theorem. Naïve Bayes models the joint distribution p(x, y) of the observation x and its class y.
ØMaximum entropy (ME) assigns the joint probability to observation and label pairs (x, y) based on a log-linear model :
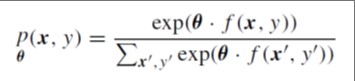 |
where: θ is a vector of weights, f is a function that maps pairs (x, y) to a binary-value feature vector
|
ØSupport vector machines (SVM) is a supervised discriminative learning algorithm for binary classification.
ØEnsemble methods combine multiple learning algorithms to obtain better predictive performance than any of the base learning algorithms alone.
Introduction in Topic Models and BERT Click to read
Introduction in Topic Models
•Topic models provide a concept representation method that transforms the high-dimensional sparse vectors in the traditional vector space model into low-dimensional dense vectors to alleviate the curse of dimensionality. can better capture polysemy and synonymy and mine implicit topics (also called concepts) in texts.
•Basic topic models:
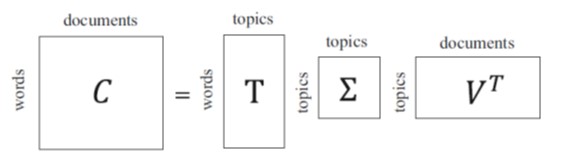
ØLatent Semantic Analysis (LSA) represents a piece of text by a set of implicit semantic concepts rather than the explicit terms in the vector space model. LSA reduces the dimension of text representation by selecting k latent topics instead of m explicit terms as
the basis for text representation using the following decomposition matrix:
ØProbabilistic latent semantic analysis (PLSA) extends latent semantic
analysis’s algebra framework to include probability.
ØLatent Dirichlet allocation (LDA) introduces a Dirichlet distribution to the document-conditional topic distribution and the topic-conditional term distribution.
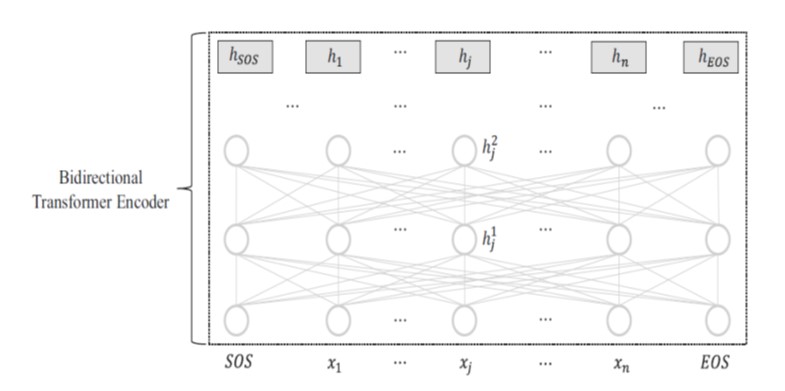
BERT: Bidirectional Encoder Representations from Transformer
•BERT is a pretraining and fine-tuning model that employs the bidirectional encoder of Transformer.
•The representation of each input token hj is learned by attending to both the left-side context, x1, · · · , xj−1 and the right-side context xj+1, · · · , xn.
•Bidirectional contexts are crucial in tasks like sequential labeling and question answering.
•The contributions of BERT:
ØBERT employs a much deeper model than GPT, and the bidirectional encoder consists of up to 24 layers with 340 million network parameters.
ØBERT designs two unsupervised objective functions, including the masked language model and next sentence prediction.
ØBERT is pretrained on even larger text datasets.
Sentiment Analysis and Opinion Mining Click to read
•The main tasks of sentiment analysis and opinion mining include the extraction, classification, and inference of subjective information in texts, such as sentiment, opinion, attitude, emotion, stance.
•Sentiment analysis techniques are naturally divided into two categories:
Ørules-based methods - perform sentiment analysis at different granularities of text based on the sentiment orientation of the words provided by a sentiment lexicon,
Ømachine learning-based methods focus on effective feature engineering for text representation and machine learning.
Case Study with Python
Common Python libraries for Text Mining Click to read
Common Python libraries for Text Mining
ØNLTK (Natural Language Toolkit) – includes powerful libraries for symbolic and statistical natural language processing that can work on different ML techniques.
ØSpaCy - open-source library for NLP in Python designed for information extraction or general-purpose natural language processing.
ØTextBlob library provides a simple API for NLP tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
ØStanford NLP contains tools useful in a pipeline, to convert a string containing human language text into lists of sentences and words, to generate base forms of those words, their parts of speech and morphological features, and to give a syntactic structure dependency parse, which is designed to be parallel among more than 70 languages.
Using NTLK Libraries for Text Mining Click to read Sentiment analysis exemplified using Bag of words method and NLTK library Click to read Text Classification using Naïve Base Click to read
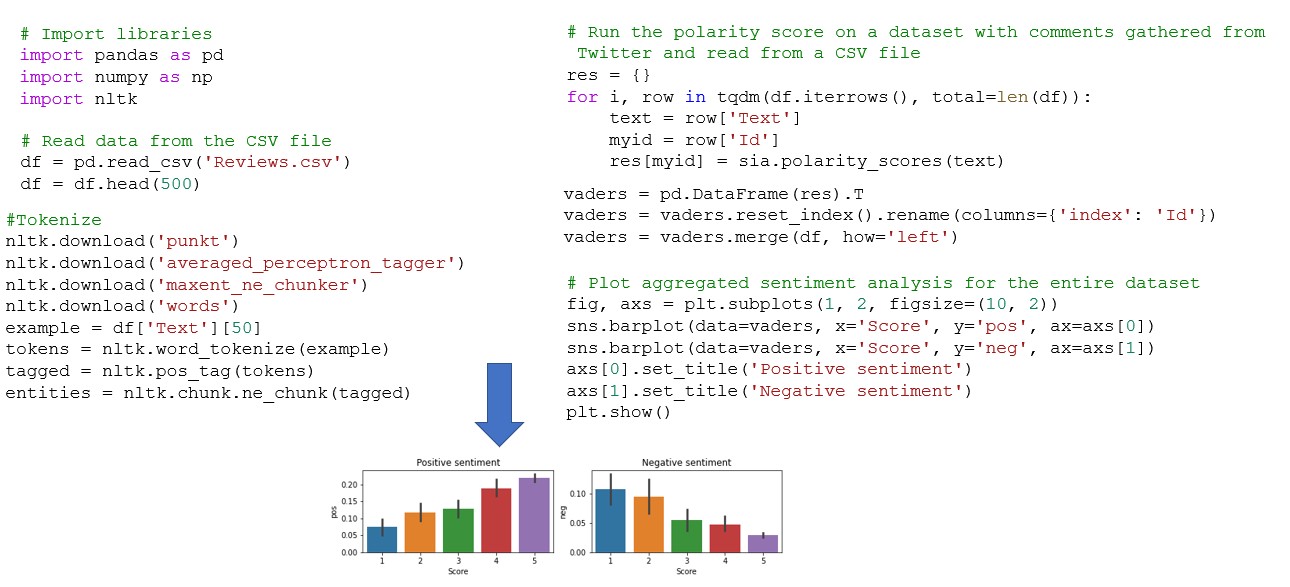
Predict the sentiment of a given review using a Naïve Bayse machine learning model

|
 Play Audio
Play Audio