|
Text Mining
Introduction
Ce este text mining? Click to read 
Text mining este o confluență a procesării limbajului natural, extragerea datelor, învățarea automată și statisticile utilizate pentru extragerea cunoștințelor din text nestructurat.
În general vorbind, text mining poate fi de două tipuri:
Întrebările utilizatorului sunt foarte clare și specifice, dar nu știu răspunsul la întrebări.
Utilizatorul cunoaște doar scopul general, dar nu are întrebări specifice și precise.
Provocări ale explorării textului Click to read
Textul în limbaj natural este nestructurat.
Majoritatea metodelor de data mining gestionează date structurate sau semi-structurate => analiza și modelarea textului nestructurat în limbaj natural este o provocare.
Explorarea de date text este de facto o tehnologie integrată de procesare a limbajului natural, clasificare a modelelor și învățare automată.
Sistemul teoretic de procesare a limbajului natural nu a fost încă pe deplin stabilit.
Principalele dificultăți cu care se confruntă explorarea textului sunt generate de :
Apariția zgomotului sau a expresiilor prost formate,
Expresii ambigue în text,
Colectarea și adnotarea dificilă a mostrelor pentru a cultiva metodele de învățare automată,
Greu de exprimat scopul și cerințele text mining
Text Mining Processing Flow Click to read
Text mining îndeplinește unele sarcini generale pentru a extrage în mod eficient texte, documente, cărți, comentarii:
Tehnici de explorare a textului
Tehnici tipice de explorare a textului Click to read
Text mining este un domeniu de cercetare care cuprinde mai multe tehnologii și tehnici :
Metodele de clasificare a textului împart un text dat în tipuri de text predefinite.
Tehnicile de grupare a textului împart un anumit set de text în diferite categorii.
Modele de subiecte = modele statistice folosite pentru a analiza subiectele și conceptele ascunse în spatele cuvintelor din text.
Analiza de sentiment a textului (text opinion mining) dezvăluie informațiile subiective exprimate de autorul unui text, adică punctul de vedere și atitudinea autorului. Textul este clasificat pe baza atitudinilor exprimate în text sau a judecăților polarității sale pozitive sau negative.
TTehnici tipice de extragere a textului (2) Click to read
Detectarea topicului se referă la analizarea și filtrarea subiectelor de text (subiecte fierbinți) de încredere pentru analiza opiniei publice, calcularea rețelelor sociale și serviciile de informare personalizate.
Extragerea informațiilor se referă la extragerea de informații faptice, cum ar fi entități, atribute ale entităților, relații dintre entități și evenimente din textul în limbaj natural nestructurat și semistructurat pe care îl formează în date structurate.
Rezumarea automată a textului generează automat rezumate folosind metode de procesare a limbajului natural.
Tehnici de pregătire și transformare a datelor Click to read
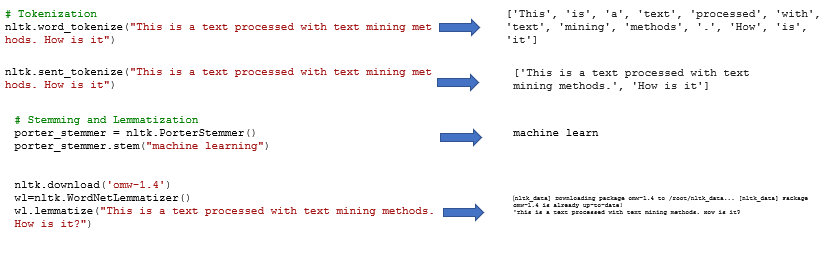
Tokenizarea se referă la un proces de segmentare a unui text dat în unități lexicale.
Eliminarea cuvintelor stop: cuvintele stop se referă în principal la cuvinte funcționale, inclusiv cuvinte auxiliare, prepoziții, conjuncții, cuvinte modale și alte cuvinte de înaltă frecvență.
Normalizarea formei cuvintelor pentru a îmbunătăți eficiența procesării textului. Normalizarea formelor de cuvinte include două concepte de bază:
Lematizare - restaurarea cuvintelor deformate în forme originale, pentru a exprima o semantică completă,
Tulpinirea - procesul de îndepărtare a afixelor pentru a obține rădăcini.
Adnotarea datelor reprezintă o etapă esențială a metodelor de învățare automată supravegheată. Dacă scara datelor adnotate este mai mare, calitatea este mai mare, iar dacă acoperirea este mai largă, performanța modelului antrenat va fi mai bună.
Bazele reprezentării textului Click to read
Modelul spațial vectorial este cea mai simplă metodă de reprezentare a textului.
Concepte de bază înrudite:
Textul este o secvență de caractere cu anumite granularități, cum ar fi fraze, propoziții, paragrafe sau un document întreg.
Termenul este cea mai mică unitate lingvistică inseparabilă care poate desemna caractere, cuvinte, fraze etc.
Ponderea termenului este ponderea atribuită unui termen în conformitate cu anumite principii, indicând importanța și relevanța acelui termen în text.
Modelul de spațiu vectorial presupune că un text respectă următoarele două cerințe: (1) fiecare termen ti este unic, (2) termenii nu au nicio ordine.
Clasificarea Textului Click to read
În clasificarea textului, un document trebuie să fie reprezentat corect și eficient pentru algoritmii de clasificare.
Selectarea unei metode de reprezentare a textului depinde de alegerea algoritmului de clasificare.

Algoritmi de bază de învățare automată pentru clasificarea textului Click to read
Algoritmi de clasificare a textului:
Naive Bayes este o colecție de clasificatoare care funcționează pe principiile teoremei lui Bayes. Naïve Bayes modelează distribuția comună p(x, y) a observației x și clasa sa y.
Entropia maximă (ME) atribuie probabilitatea comună perechilor de observare și etichetare (x, y) pe baza unui model log-liniar:
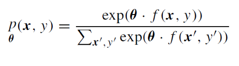
Algoritmi de clasificare a textului:
Naive Bayes este o colecție de clasificatoare care funcționează pe principiile teoremei lui Bayes. Naïve Bayes modelează distribuția comună p(x, y) a observației x și clasa sa y.
Entropia maximă (ME) atribuie probabilitatea comună perechilor de observare și etichetare (x, y) pe baza unui model log-liniar:
unde: θ este un vector de greutăți, f este o funcție care mapează perechile (x, y) la un vector caracteristic cu valori binare
Mașini vectoriale suport (SVM) este un algoritm de învățare discriminativ supravegheat pentru clasificarea binară.
Metodele de ansamblu combină mai mulți algoritmi de învățare pentru a obține o performanță predictivă mai bună decât oricare dintre algoritmii de învățare de bază.
unde: θ este un vector de greutăți, f este o funcție care mapează perechile (x, y) la un vector caracteristic cu valori binare
Mașini vectoriale suport (SVM) este un algoritm de învățare discriminativ supravegheat pentru clasificarea binară.
Metodele de ansamblu combină mai mulți algoritmi de învățare pentru a obține o performanță predictivă mai bună decât oricare dintre algoritmii de învățare de bază.
Introducere în Modele de topic Click to read
Modelele de topic oferă o metodă de reprezentare a conceptului care transformă vectorii rari de dimensiuni înalte din modelul tradițional de spațiu vectorial în vectori denși de dimensiuni joase pentru a atenua blestemul dimensionalității, poate surprinde mai bine polisemia și sinonimia și să mine subiecte implicite (numite și concepte) în texte.
Modele de teme de bază:
Analiza semantică latentă (LSA) reprezintă o bucată de text printr-un set de concepte semantice implicite, mai degrabă decât termenii explici din modelul spațiului vectorial. LSA reduce dimensiunea reprezentării textului selectând k subiecte latente în loc de m termeni explici ca

Analiza semantică latentă probabilistică (PLSA) extinde semantica latentă în cadrul algebric al analizei pentru a include probabilitatea.
Alocarea Dirichlet latentă (LDA) introduce o distribuție Dirichlet în distribuția de subiecte condiționată de document și în distribuția de termeni condiționată de subiect.
BERT: Reprezentări codificatoare bidirecționale de la Transformer Click to read
BERT este un model de preinstruire și reglare fină care utilizează codificatorul bidirecțional Transformer.
Reprezentarea fiecărui jeton de intrare hj este învățată ținând cont atât de contextul din partea stângă, x1, · · · , xj−1, cat si contextul din dreapta xj · · · , xn.

Contextele bidirecționale sunt cruciale în sarcini precum etichetarea secvențială și răspunsul la întrebări.
Contribuțiile BERT :
BERT folosește un model mult mai profund decât GPT, iar codificatorul bidirecțional constă din până la 24 de straturi cu 340 de milioane de parametri de rețea.
BERT proiectează două funcții obiective nesupravegheate, inclusiv modelul de limbaj mascat și predicția următoarei propoziții.
BERT is pretrained on even larger text datasets.
Analiza de sentiment și explorarea opiniei Click to read
Sarcinile principale ale analizei sentimentelor și ale analizei opiniei includ extragerea, clasificarea și inferența informațiilor subiective din texte, cum ar fi sentimentul, opinia, atitudinea, emoția, poziția.
Tehnicile de analiză a sentimentelor sunt împărțite în mod natural în două categorii:
metode bazate pe reguli - efectuează o analiză a sentimentelor la diferite granularități ale textului pe baza orientării sentimentului a cuvintelor furnizate de un lexic de sentimente,
metodele bazate pe învățarea automată se concentrează pe inginerie eficientă a caracteristicilor pentru reprezentarea textului și învățarea automată.
Studiu de caz folosind Python
Biblioteci comune Python pentru explorarea textului Click to read
NLTK (Natural Language Toolkit) – include biblioteci puternice pentru procesarea simbolică și statistică a limbajului natural care poate funcționa pe diferite tehnici
ML.
SpaCy - bibliotecă open-source pentru NLP în Python, concepută pentru extragerea informațiilor sau procesarea limbajului natural cu scop general.
TextBlob library oferă un API simplu pentru sarcini NLP, cum ar fi etichetarea parțială a vorbirii, extragerea expresiilor nominale, analiza sentimentelor, clasificarea,
traducerea și multe altele.
Stanford NLP conține instrumente utile într-o conductă, pentru a converti un șir care conține text în limbajul uman în liste de propoziții și cuvinte, pentru a genera
forme de bază ale acestor cuvinte, părțile lor de vorbire și caracteristicile morfologice și pentru a oferi o analiză de dependență a structurii sintactice, care este
concepută. să fie paralele între peste 70 de limbi.
Utilizarea bibliotecilor NTLK pentru extragerea textului Click to read SUtilizarea bibliotecilor NTLK pentru extragerea textului (2) Click to read Analiza de sentiment exemplificată folosind metoda Bag of words și biblioteca NLTK Click to read Analiza de sentiment exemplificată folosind metoda Bag of words și biblioteca NLTK Click to read Clasificarea textului folosind Naïve Base Click to read
Preziceți sentimentul unei anumite recenzii folosind un model de învățare automată Naïve Bayse.

Rezumat
Rezumat Click to read |
 Redare audio
Redare audio