DataScience Training






|
SQL und GitHub Einf�hrung in SQL Hintergrundinformationen Click to read
 SQL: die weltweite Standardsprache für die Verwaltung und Analyse von Datenbanken Structured Query Language (SQL) ist eine weit verbreitete Datenbanksprache, die für die Verwaltung und Bearbeitung relationaler Datenbanken konzipiert ist. Sie ist ein leistungsfähiges Werkzeug, mit dem Benutzer:innen Daten auf verschiedene Weise analysieren, manipulieren und verarbeiten können, was sie zu einer beliebten Wahl in vielen Branchen und Anwendungsbereichen macht, darunter Finanzen, E-Commerce, Gesundheitswesen und Behörden. Eine der wichtigsten Eigenschaften von SQL ist seine Flexibilität. Es bietet eine Standardmethode für die Pflege und Verarbeitung großer Datenmengen und ist damit die erste Wahl für Unternehmen, die große Mengen an Informationen verwalten müssen. Dank seiner Flexibilität lassen sich auch individuelle Abfragen und Berichte erstellen, die den Nutzern wertvolle Einblicke in die Daten geben, mit denen sie arbeiten. Neben seiner Flexibilität zeichnet sich SQL auch durch seine Fähigkeit aus, Daten schnell und effizient zu verarbeiten und zu manipulieren. Durch den Einsatz komplexer SQL-Anweisungen und Indizierungstechniken kann SQL Daten schnell auffinden und abrufen, was besonders bei der Arbeit mit großen Datenbanken wichtig ist. Ein weiterer Vorteil von SQL ist seine Benutzerfreundlichkeit. Für die meisten Benutzer:innen ist es relativ einfach zu erlernen und zu verwenden, was es zu einer beliebten Wahl für Unternehmen und Organisationen jeder Größe macht. Außerdem gibt es zahlreiche Quellen, um die Sprache zu erlernen, von Online-Tutorials und -Kursen bis hin zu Lehrbüchern und Handbüchern. Trotz seiner vielen Vorteile hat SQL auch einige Einschränkungen. Zum Beispiel ist es nicht immer die beste Wahl für die Arbeit mit unstrukturierten Daten, wie Bildern, Videos oder Audiodateien. Außerdem ist es möglicherweise nicht die effektivste Wahl für bestimmte Arten von Analysen, z. B. solche, die fortgeschrittene statistische Techniken erfordern.  Zweck von SQL Eine der Hauptanwendungen von SQL ist der Abruf von Daten aus einer Datenbank. Dies kann die Auswahl bestimmter Datenspalten, das Filtern von Daten nach bestimmten Kriterien oder die Kombination von Daten aus mehreren Tabellen umfassen. Nehmen wir zum Beispiel an, wir haben eine Datenbank mit Kunden und deren Bestellungen. Mit SQL können wir leicht eine Liste aller Bestellungen für eine:n bestimmte:n Kund:in oder alle Bestellungen für einen bestimmten Zeitraum abrufen. Eine weitere Anwendung von SQL ist das Hinzufügen neuer Daten zu einer Datenbank, das Bearbeiten vorhandener Daten oder das Löschen nicht mehr benötigter Daten. Dies kann besonders nützlich sein, wenn wir große Datenmengen auf einmal aktualisieren müssen. Wenn wir z. B. die Lieferadresse für alle Kund:innen, die in einer bestimmten Postleitzahl wohnen, aktualisieren müssen, können wir diese Änderung schnell und einfach mit SQL vornehmen. Neben der Verwaltung von Daten kann SQL auch dazu verwendet werden, ganze Tabellen in Datenbanken zu erstellen und zu verwalten. Dazu gehört das Erstellen neuer Tabellen, das Ändern bestehender Tabellen und das Löschen von Tabellen, die nicht mehr benötigt werden. Wenn wir z. B. eine neue Tabelle zur Erfassung der Verkaufsdaten eines Unternehmens erstellen möchten, können wir mit SQL die Struktur der Tabelle definieren und die Datentypen für jede Spalte festlegen. Schließlich ist SQL besonders gut für die Verarbeitung großer Datenmengen geeignet. Das liegt daran, dass es auf hohe Effizienz ausgelegt ist und komplexe Abfragen und Operationen mühelos bewältigen kann. Damit ist es die beste Wahl für Unternehmen und Organisationen, die regelmäßig große Datenmengen verwalten und analysieren müssen.
Relationale Datenbanken sind der Schl�ssel Click to read
Relationale Datenbanken sind der Schlüssel
SQL-Anweisungen Click to read
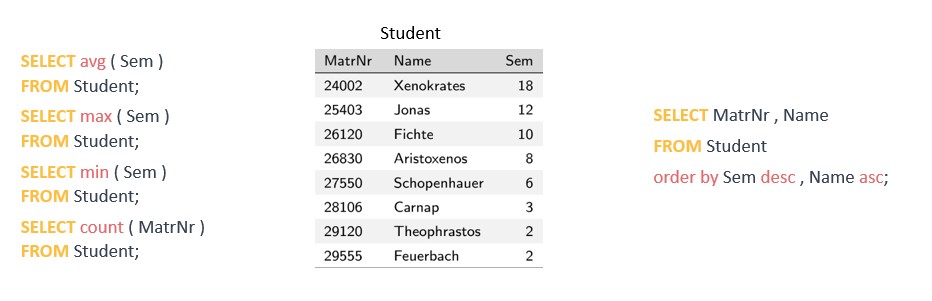
Struktur und Syntax von SQL-Anweisungen SELECT: Dient zum Abrufen von Daten aus einer oder mehreren Tabellen Die Struktur und Syntax von SQL-Anweisungen kann je nach verwendetem Datenbankmanagementsystem (DBMS) variieren. Es gibt jedoch einige allgemeine Richtlinien, die für die meisten SQL-Anweisungen gelten. Eine grundlegende SQL-Anweisung besteht normalerweise aus den folgenden Elementen:
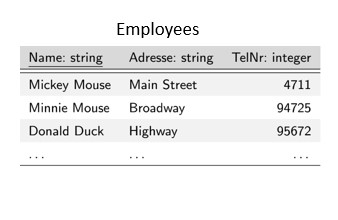
Schlüsselwort: Das Schlüsselwort oder die Klausel, die die Art des auszuführenden Vorgangs angibt Eine einfache SELECT-Anweisung würde zum Beispiel so aussehen: SELECT spalte1, spalte2 FROM tabellen_name; In dieser Anweisung ist "SELECT" das Schlüsselwort, "column1, column2" sind die Argumente und "table_name" ist die Tabelle, aus der die Daten abgerufen werden. Das Semikolon am Ende der Anweisung zeigt das Ende der SQL-Anweisung an. SELECT-Anweisungen Ein einfaches Beispiel für eine SELECT-Anweisung in Bezug auf unsere relationale Datenbank könnte wie folgt aussehen: SELECT * FROM Mitarbeitende; "SELECT" ist das Schlüsselwort und " Diese SQL-Anweisung ruft alle Daten aus unserer Tabelle "Mitarbeitende" ab. Das * steht für alle und in diesem Fall für alle Spalten. SELECT Name, TelNr FROM Mitarbeitende; Betrachten wir nun die speziellen Argumente FROM und WHERE: FROM bestimmt die Tabelle oder die Tabellen für diese Abfrage WHERE wird verwendet, um eine Bedingung zu unserer Abfrage hinzuzufügen; wenn die Bedingung ein Text ist, schließen wir den Text in einfache Anführungszeichen ein Wenn wir z. B. nur die Telefonnummern unserer Mitarbeitenden mit dem Nachnamen Maus haben wollen, dann verwenden wir: SELECT Name, TelNr FROM Mitarbeitende WHERE Name = 'Maus'; SELECT-Anweisungen sind sehr leistungsfähig und ermöglichen Data Scientists verschiedene Einblicke. Weitere spezielle Argumente findest du im Anhang zu diesem Skript.
INSERT INTO tabelle_name (spalte1, spalte2 ...) VALUES (wert1, wert2 ... wertX); Nach INSERT INTO folgt der Name der Tabelle, in die die Daten eingefügt werden sollen, im Beispiel "table_name". Wenn wir zum Beispiel Daten in unsere Tabelle "Mitarbeitende" mit den Spalten "Name", "Adresse" und "TelNr" einfügen, könnte die SQL-Anweisung zum Einfügen eines neuen Datensatzes wie folgt aussehen: UPDATE: Der UPDATE-Befehl wird verwendet, um vorhandene Daten in einer Tabelle in einer Datenbank zu ändern. Mit diesem Befehl können wir die neuen Werte angeben, welche die vorhandenen Werte ersetzen sollen, und die Daten nach bestimmten Kriterien zu filtern. UPDATE tabelle_name UPDATE table_name gibt den Namen der zu aktualisierenden Tabelle an. DELETE: Der DELETE-Befehl wird verwendet, um Daten aus einer Tabelle in einer Datenbank zu entfernen. Er ermöglicht es uns, die Daten nach bestimmten Kriterien zu filtern und alle oder eine Teilmenge der Daten, die diesen Kriterien entsprechen, zu entfernen. DELETE FROM table_name WHERE {condition}; DELETE FROM table_name gibt den Namen der Tabelle an, aus der Zeilen gelöscht werden sollen. WHERE {Bedingung} ist eine optionale Klausel, die die Bedingung(en) angibt, die erfüllt sein muss (müssen), damit die Zeilen gelöscht werden. Wenn keine Bedingung angegeben wird, werden alle Zeilen in der Tabelle gelöscht! Beispiele für gültige Bedingungen: Bei der Verwendung der DELETE-Anweisung ist Vorsicht geboten, da sie Daten dauerhaft aus einer Tabelle entfernt. Es wird empfohlen, eine Sicherungskopie der Daten zu erstellen oder eine Transaktion zu verwenden, um die Änderungen bei Bedarf zurückzusetzen. Zusammenfassend lässt sich sagen, dass SQL eine leistungsstarke und flexible Datenbanksprache ist, die in vielen verschiedenen Branchen und Anwendungsbereichen eingesetzt wird. Ihre Benutzer:innenfreundlichkeit, Flexibilität und Effizienz machen sie zu einer hervorragenden Wahl für Unternehmen und Organisationen, die große Datenmengen verarbeiten und verwalten müssen. Mit seinen vielen Vorteilen und den verfügbaren Lernressourcen ist SQL ein wertvolles Werkzeug für jeden, der mit relationalen Datenbanken arbeitet.
|
|
GitHub verstehen Zweck von GitHub Verwaltung von umfangreichen Software-Codes Click to read
Für alle Softwareentwickler:innen ist die Verwaltung des Codes ein wesentlicher Bestandteil der Programmierung. Versionskontrollsysteme ermöglichen es Entwickler:innen, ihre Codeänderungen zu kontrollieren, mit anderen zusammenzuarbeiten und ihre Projekte effizient zu verwalten. Ein beliebtes Versionskontrollsystem ist Git, und GitHub ist ein cloudbasierter Versionskontrolldienst für Softwareentwicklungsprojekte, der auf Git aufbaut. GitHub bietet eine benutzer:innenfreundliche Oberfläche zum Erstellen und Verwalten von Git-Repositories sowie Tools für die Zusammenarbeit mit anderen Entwicklern an einem Projekt. GitHub kann sowohl für persönliche als auch für kommerzielle Projekte genutzt werden und ist in der Basisversion kostenlos. GitHub kann als eine Art soziales Netzwerk für Softwareentwickler:innen bezeichnet werden. Mitglieder können einander folgen, die Arbeit anderer bewerten, Updates zu bestimmten Projekten erhalten und öffentlich oder privat kommunizieren. Es ermöglicht Entwickler:innen, ihre Arbeit zu teilen, von anderen zu lernen und eine Gemeinschaft aufzubauen. GitHub bietet auch eine umfassende Reihe von Projektmanagement-Tools, die es Entwickler:innen leicht machen, ihre Projekte zu verwalten. Dazu gehören Tools zum Verfolgen von Problemen, zum Organisieren von Aufgaben und zum Zusammenarbeiten mit anderen. Seit Ende 2018 ist GitHub Inc. im Besitz von Microsoft.
Was ist Versionskontrolle? Click to read
Bei der Arbeit an komplexen Softwareprojekten kann die Verfolgung von Änderungen und die Verwaltung mehrerer Codeversionen eine Herausforderung darstellen. Versionskontrollsysteme wie Git bieten eine Lösung für dieses Problem, indem sie die Änderungen verfolgen und aufzeichnen. Git bietet Funktionen zum Wiederherstellen alter Versionen eines Projekts, Vergleichen, Analysieren, Zusammenführen von Änderungen und vieles mehr. Dieser Prozess wird Versionskontrolle genannt und hilft Entwickler:innen, den Überblick über die Geschichte ihres Codes zu behalten. Git ist nicht das einzige verfügbare Versionskontrollsystem. Andere Versionskontrollsysteme wie Perforce, Mercurial, CVS und SVN sind ebenfalls verfügbar. Aufgrund seiner Flexibilität, Geschwindigkeit und Benutzer:innenfreundlichkeit ist Git jedoch das beliebteste und am weitesten verbreitete Versionskontrollsystem unter Entwickler:innen. Eines der einzigartigen Merkmale von Git ist, dass es sich um ein dezentrales Versionskontrollsystem handelt. Im Gegensatz zu anderen Systemen ist Git nicht auf einen zentralen Server angewiesen, um alte Versionen von Dateien aufzubewahren. Stattdessen arbeitet es vollständig lokal und speichert diese Daten in Ordnern auf der Festplatte einzelner Benutzer:innen. Dies wird als Repository bezeichnet. Dies ermöglicht es Entwickler:innen, offline an ihrem Code zu arbeiten, und erleichtert die Verfolgung von Änderungen, ohne auf einen zentralen Server angewiesen zu sein. Wenn Benutzer:innen mit anderen an demselben Code arbeiten möchte, können sie eine Kopie ihres Repositorys online bereitstellen, auf die das gesamte Team zugreifen kann. So können mehrere Entwickler an der gleichen Codebasis arbeiten, ohne die Änderungen der anderen zu überschreiben. |
|
Wie man sie benutzt Installieren Sie es auf Ihrem Ger�t Installieren Click to read
Um Github produktiv nutzen zu können, benötigst du Git auf deinem lokalen Computer. Es gibt viele Git-Programme, die kostenlos oder kostenpflichtig genutzt werden können: Windows - "Git für Windows" bietet einen GUI-Client und einen BASH-Befehlszeilenemulator. https://git-scm.com/downloads/win oder Linux - öffne einfach ein neues Terminal und installiere Git über den Paketmanager deiner Linux-Distribution. Für Ubuntu lautet der Befehl z. B. sudo apt-get install git
Ein Konto erstellen und GitHub konfigurieren Click to read
Bevor du es verwenden kannst, musst du ein Github-Konto auf www.github.com.
Es gibt verschiedene Konfigurationen für das Aussehen und die Funktionalität des Clients. Entscheide nach deinen Vorlieben, um effizient zu arbeiten. Wichtig ist jedoch die Konfiguration des Benutzernamens und der entsprechenden E-Mail-Adresse Alle Aktivitäten in Git sind mit dem jeweiligen Benutzernamen und der in der Konfiguration angegebenen E-Mail-Adresse verknüpft! Das macht Änderungen nachvollziehbar, weil andere Nutzer:innen immer wissen, wer die jeweiligen Änderungen vorgenommen hat, und schafft Übersicht in Projekten, an denen viele Entwickler:innen arbeiten. Wie man GitHub verwendet Click to read
Bei der Arbeit mit Git ist es wichtig, die Terminologie zu verstehen, um es effektiv nutzen zu können. Ein Repository, oder kurz Repo, ist ein Ordner, in dem alle Dateien und ihre Versionshistorie gespeichert werden. Es ist der zentrale Ort zum Verwalten und Organisieren von Code. Ein Repository kann auf einem entfernten Server wie GitHub oder Bitbucket gehostet werden, oder es kann lokal auf Ihrem Computer gespeichert werden. Ein Branch ist ein Arbeitsbereich, in dem du isolierte Änderungen vornehmen kannst, die sich nicht auf andere auswirken und eine eigene Historie haben. Er ist wie eine separate Zeitleiste, in der du mit Änderungen experimentieren kannst, ohne die Hauptcodebasis zu beeinträchtigen. Die Entwickler:innen können gleichzeitig an verschiedenen Branches arbeiten, was die Zusammenarbeit erleichtert und Konflikte vermeidet. Ein Commit ist eine gespeicherte Aufzeichnung der Änderungen, die an einer Datei innerhalb des Projektarchivs vorgenommen wurden. Es handelt sich um den Zustand des Projektarchivs zu einem bestimmten Zeitpunkt. Ein Schnappschuss, zu dem der Code wiederhergestellt werden kann. Commits sind in Git unverzichtbar, da sie es ermöglichen, Änderungen im Laufe der Zeit zu verfolgen und bei Bedarf zu einer früheren Version des Codes zurückzukehren. Nachdem Aktualisierungen an einem Repository vorgenommen wurden, können andere Entwickler:innen alle Änderungen mit einem Pull Request oder PR herunterladen. Eine Pull-Anfrage ist eine Anfrage, Änderungen von einem Branch in einen anderen zusammenzuführen. Dies ermöglicht es den Entwickler:innen, die Änderungen zu überprüfen und zu genehmigen, bevor sie in die Hauptcodebasis aufgenommen werden. Ein Push ist der Prozess, bei dem eine lokale Änderung zum entfernten Repository hinzugefügt wird. Wenn du deine Änderungen pusht, werden sie für andere sichtbar und können heruntergeladen werden. Dies ist ein wichtiger Schritt in der Zusammenarbeit mit anderen Entwickler:innen. Nachdem eine Pull-Anfrage genehmigt wurde, wird der Commit von einem Branch zum anderen zusammengeführt. Beim Merging werden die Änderungen von einem Branch in einen anderen, in der Regel den Haupt-Branch, zusammengeführt. Dieser Prozess stellt sicher, dass alle Änderungen in die Hauptcodebasis aufgenommen werden. Ein Klon ist eine voll funktionsfähige Kopie eines Projekts. Das Kopieren eines Repositorys von einem entfernten Server ist ein Klonen. Auf diese Weise kannst du eine vollständige Kopie auf dem lokalen Rechner haben, was die Arbeit an deinem Code erleichtert, ohne auf eine Internetverbindung angewiesen zu sein. Erste Schritte in Github Click to read
Wenn du Git verwendest, musst duzunächst einen Ordner erstellen mkdir learning-git (=Verzeichnis erstellen) in dem das Repository für jedes Programm oder Projekt erstellt werden kann Anschließend kannst du ein lokales und ein Online-Repositorium verknüpfen mit https://github.com/[username]/[projectname].git Git arbeitet mit dem Konzept einer "Staging Area". Zu Beginn ist der Staging-Bereich leer. Dateien können mit dem Befehl git add hinzugefügt werden (oder sogar einzelne Zeilen und Teile von Dateien) und schließlich wird mit git commit alles übertragen (ein Schnappschuss erstellt):
Dann können die lokalen Commits auf den Server übertragen werden, was jedes Mal geschieht, wenn wir das entfernte Repository aktualisieren wollen Sobald dies geschehen ist, können andere Entwickler:innen die Änderungen aus dem entfernten Repository mit einem einzigen Befehl herunterladen Um ein ganzes Programm oder Projekt zu klonen, verwende Branch-bezogene Befehle (branch) Click to read
Bei der Entwicklung einer neuen Funktion in der Softwareentwicklung ist es am besten, an einer Kopie des Originalprojekts, einem so genannten Branch (branch), zu arbeiten. Ein Branch ist eine separate Kopie der Codebasis, die es den Entwicklern ermöglicht, Änderungen vorzunehmen, ohne die Live-Version des Codes zu beeinflussen.
Mehrere Versionen desselben Features können in verschiedenen Branches entwickelt und dann verglichen werden, um die beste Version zu ermitteln: Branches ermöglichen es den Entwickler:innen, mit verschiedenen Ansätzen für eine Funktion zu experimentieren und die Ergebnisse zu vergleichen, bevor die Änderungen in die Hauptcodebasis übernommen werden.
Wechsle auf den neu erstellten Branch, indem du Um zwei Branches zusammenzuführen, wechsele zu einem und verwende Um einen Branch zu löschen, verwende Zusammenfassend lässt sich sagen, dass viele Unternehmen GitHub nutzen. Wenn du also einen Job suchst, bist du gut beraten, wenn du dich bereits mit GitHub auskennst. GitHub ist auch eine Lern- und Kooperationsplattform. Erforsche es und erweitere dein Wissen und deine Community. |


Keywords
SQL Github
Objectives/goals:- 1. Verstehen, wann man SQL verwenden sollte
2. Wichtige Anwendungsbereiche von SQL
3. Die grundlegenden SQL-Befehle
4. Wie man gemeinsam im Team Code entwickelt
5. Grundlegende Funktionalitäten von GitHub
• Dieser Kurs gibt eine kurze Einführung in die wichtigsten Programmiersprachen und Tools, die Data Scientists täglich verwenden.
• Es wird erläutert, in welchem Zusammenhang und zu welchem Zweck sie üblicherweise verwendet werden, und es werden die wichtigsten Befehle für Anfänger:innen vorgestellt:
o SQL ist zu einem Eckpfeiler der modernen Datenverwaltung geworden. In diesem Kurs werden wir verschiedene Möglichkeiten erkunden, wie SQL zum Abrufen von Daten aus Datenbanken verwendet werden kann.
o Wir werden besprechen, was GitHub ist, welche Funktionen es bietet und wie Softwareentwickler davon profitieren können.
• Am Ende des Kurses kennen die Teilnehmer:innen das Tätigkeitsfeld und die gebräuchlichsten Befehle.
Related training material






