|
Introducere în învățarea automată (machine learning)
Introducere
De ce ar trebui să învețăm despre învățarea automată Click to read 
Statistica și învățarea automată oferă principalele instrumente pentru munca unui cercetător în domeniul datelor. Înțelegerea diferitelor metode de învățare automată - cum funcționează, care sunt principalele lor avantaje și cum se evaluează performanța lor - vă poate ajuta să luați decizii mai bune referitoare la când să le utilizați și oferă versatilitate în analiza datelor.
IA, ML, DL și știința datelor
Definiții Click to read
➢IA: Inteligența artificială
➢ML: Machine Learning (învățarea automată)
➢DL: Deep Learning (învățarea profundă)
➢DS: Data Science (știința datelor)
IA: Inteligența artificială
Un sistem informatic care poate îndeplini sarcini asociate în mod normal cu inteligența umană
De exemplu: percepția vizuală, recunoașterea vorbirii, luarea deciziilor, traducerea textelor
IA generală vs. IA restrânsă:
IA generală poate gestiona toate sarcinile, IA restrânsă doar un subset selectat de sarcini. În prezent, nu există un sistem de IA care să poată fi considerat IA general, iar dacă un astfel de sistem va putea exista în viitor este o chestiune intens dezbătută.
IA: Inteligența artificială
Un sistem informatic care poate îndeplini sarcini asociate în mod normal cu inteligența umană
de exemplu: percepția vizuală, recunoașterea vorbirii, luarea deciziilor, traducerea între limbi
Dacă algoritmul...
... constă în instrucțiuni ce trebuie parcurse pas cu pas pentru a realiza activitatea
atunci este IA simbolică
... detectează un model bazat pe un volum mare de date/exemple și utilizează acest model pentru a realiza activitatea
atunci este învățarea automată
ML: Machine Learning (învățare automată)
În loc să programeze fiecare pas, o mașină este programată pentru a găsi modele și „învață” pe baza exemplelor. Există o zonă mare de suprapunere cu Statistica.
➢Salvează mii de linii de cod
➢Flexibilă:
|
dacă datele se modifică,
|
programul se adaptează.
|
 |
 |
ML: Machine Learning
În loc să programeze fiecare pas, o mașină este programată pentru a găsi modele și „învață” pe baza exemplelor. Există o zonă mare de suprapunere cu Statistica.
➢AI: Inteligenţă artificială
Un sistem informatic care poate îndeplini sarcini ce necesită în mod normal inteligență umană
➢ML: Machine Learning
În loc să programeze fiecare pas, o mașină este programată pentru a găsi modele și „învață” pe baza exemplelor. Există o zonă mare de suprapunere cu Statistica.
➢DS: Data Science (Știința datelor)
Folosește metode din Machine Learning și Statistică pentru a rezolva probleme și a lua decizii pe baza datelor.
➢DL: Deep Learning (învățarea profundă)
În prezent, una dintre cele mai populare și de succes metode de învățare automată. Bazat pe algoritmi de rețele neuronale cu mai multe straturi (vezi Unitatea 2, Secțiunea 5).
➢ Salvează mii de linii de cod
➢ Flexibil: dacă datele se modifică, programul se adaptează.
➢ Rezolvă probleme pentru care nu avem o soluție pas cu pas: de ex. recunoașterea imaginii și a sunetului
➢ Joacă jocuri și ne bate
Tipuri de machine learning (învățare automată) Click to read
Algoritmii de învățare automată pot fi subdivizați în trei tipuri diferite.
➢Învățare supervizată (supervised learning)
➢ Învățare nesupervizată (unsupervised learning)
➢ Învățare prin recompensă (reinforcement learning)
➢ Învățarea supervizată (supervised learning)
În învățarea supervizată, un algoritm primește „date etichetate” ca intrare “date de antrenament”: datele etichetate sunt seturi de date în care fiecare instanță (exemplu) constă din variabile independente și valoarea variabilei țintă care ar trebui să fie determinată pe baza variabilelor independente. Cu alte cuvinte, aceasta este pur și simplu învățare prin exemplu. Scopul algoritmului este de a detecta un model care îi va permite să determine corect valoarea variabilei țintă, atunci când variabilele independente sunt cunoscute.
Învățarea supravegheată se numește clasificare, atunci când variabila țintă este o categorie – de exemplu, stabilirea dacă un solicitant de împrumut prezintă sau nu un risc ridicat, pe baza istoricului demografic și anterior de creditare. Se numește regresie atunci când variabila țintă este continuă – de exemplu, prezicerea creșterii PIB-ului unei națiuni pe baza factorilor economici actuali.
➢ Învățare nesupervizat
Învățarea nesupervizată este utilizată pentru a detecta tipare în datele neetichetate. Clustering (încercarea de a determina grupuri similare în date, fără a ști a priori ce grupuri să caute) sau metodele de reducere a dimensiunii (cum ar fi analiza componentelor principale sau LDA) sunt cele mai populare tipuri de învățare nesupravegheată.
➢Învățare prin recompensă (Reinforcement learning - RL)
Învățarea prin recompensă este utilizată pentru a identifica o strategie optimă în situațiile în care agentul algoritmic este obligat să interacționeze cu un mediu dat și să ia o serie de decizii, înainte ca rezultatul final să fie cunoscut (adică feedback-ul nu este imediat: succes vs eșec, câștig vs pierde). Metodele RL sunt cel mai frecvent utilizate în jocuri sau în conducerea autonomă și pentru mișcarea roboților.
Înainte de a trece la examinarea diferitelor tipuri de algoritmi de învățare automată, un cuvânt pentru înțelepți
➢învățarea automată este un subiect empiric
➢a priori, de obicei nu există „o metodă corectă de aplicat”
➢va trebui să:
➢colectați cerințele pentru cazul particular de utilizare,
➢încercați câteva metode diferite (Unitatea 2),
➢și apoi să le evaluați în funcție de valorile alese (Unitatea 3) și cerințele (de exemplu, poate că acuratețea nu este singurul factor important, ci și explicabilitatea),
➢pentru a determina care metodă funcționează „cel mai bine”.
Algoritmi de învățare automată
Naive Bayes Click to read
Naïve Bayes este un algoritm de clasificare simplu, care este adesea folosit ca referință în procesarea limbajului natural.
Naïve Bayes folosește teorema lui Bayes pentru a transforma problema determinării probabilității unei instanțe aparținând clasei Y, având în vedere atributele sale xi, în problema evaluării frecvenței atributului xi, având în vedere că instanța aparține clasei Y.
Poate oferi rezultate bune atunci când:
➢toate atributele sunt la fel de importante în determinarea clasei țintă,
➢pentru o clasă țintă anume, atributele sunt independente reciproc.
Naive Bayes are diferite variante:
➢Gaussian NB: folosit atunci când variabilele atribut sunt numerice și se poate presupune că urmează o distribuție gaussiană
➢Simplu NB: folosit când variabilele atribut sunt categoriale
➢Multi-nomial NB: cel mai adesea folosit în contexte de procesare a limbajului natural, unde atributele sunt cuvinte dintr-un document.
Arbori de decizie Click to read
Arborii de decizie reprezintă atât o modalitate de reprezentare a informațiilor, cât și un algoritm pentru detectarea modelelor în date.
Aici ne concentrăm pe algoritmul de detectare a șabloanelor, dar reprezentăm și informațiile obținute în proces folosind un arbore de decizie.
➢Arborele de decizie este compus din noduri și ramuri.
➢Fiecare nod este un atribut și are ramuri în funcție de valorile sale. De exemplu, dacă un atribut este „an în facultate” și valorile posibile ale atributului sunt (Boboc, Anul 2, Junior, Senior), atunci nodul corespunzător „an în facultate” ar avea 4 ramuri.
➢Arborii de decizie sunt parcurși de la nodul rădăacină în jos: la fiecare nod, trebuie luată o decizie cu privire la ce ramură trebuie urmată în continuare, pe baza valorii (valorilor) unui anumit atribut (atribute).
Random forests Click to read
Random forests reprezintă un tip de „învățare de ansamblu” – o clasă de metode care combină modele pentru a îmbunătăți acuratețea predictivă prin diversitate.
➢Random forests constau într-o serie de arbori de decizie aleși aleatoriu și
➢combină previziunile lor
➢Random forests variază în funcție de numărul de copaci și de adâncimea fiecărui copac.
Rețele neuronale Click to read
|
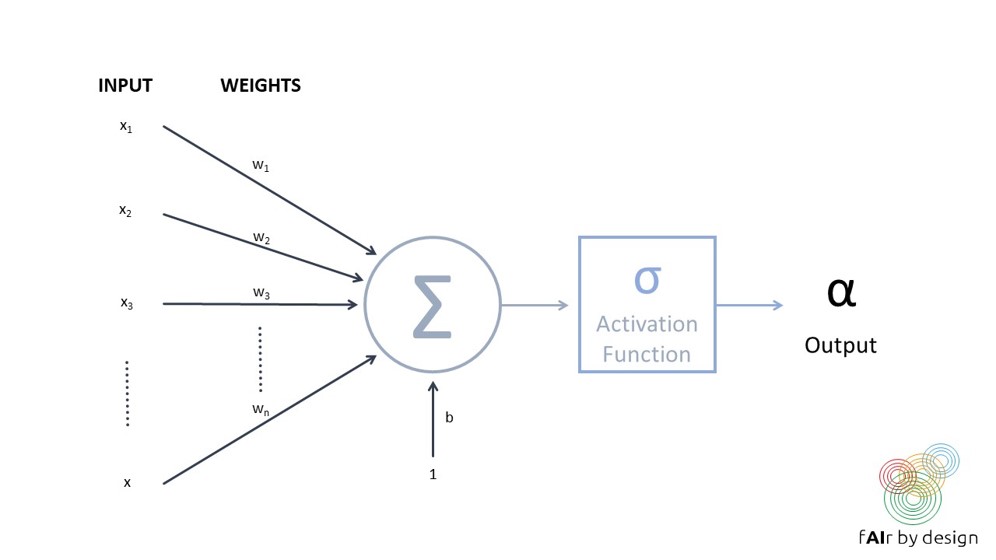
O rețea neuronală constă dintr-o serie de unități interconectate (așa-numiții „neuroni”), precum cea prezentată în figura din dreapta.
Fiecare neuron preia mai multe intrări, atribuie fiecărei intrări o pondere, apoi le combină și le rulează printr-o funcție de activare, pentru a produce o singură ieșire.
|
 |
|
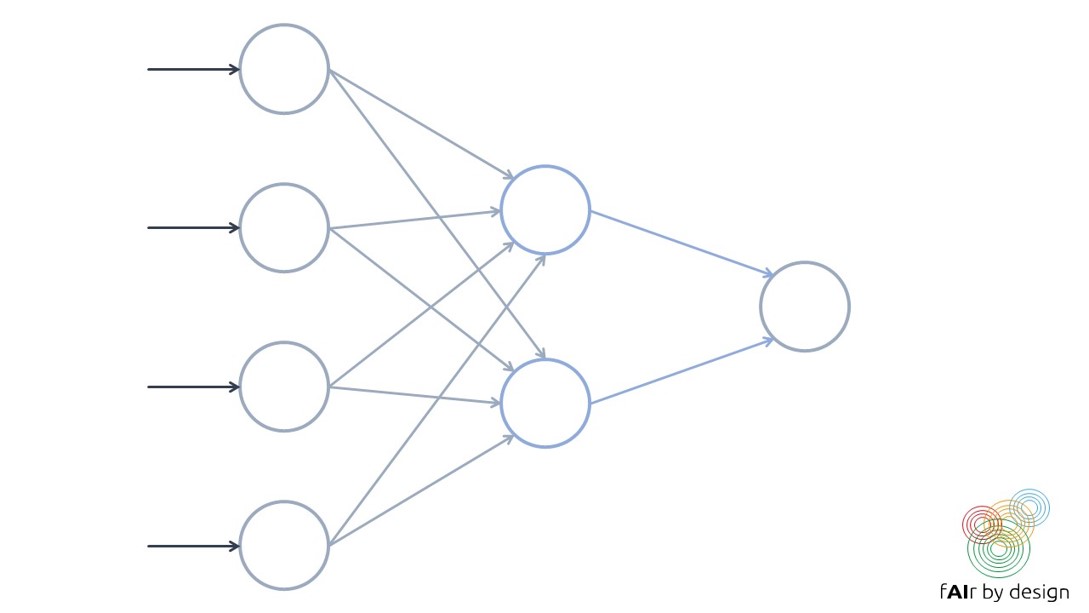
O rețea neuronală se formează prin organizarea așa-numiților neuroni în straturi.
Antrenarea unei rețele neuronale reprezintă încercarea de a stabili valorile pentru ponderile rețelei care minimizează eroarea de predicție a datelor de antrenament (măsurată de o funcție de pierdere dată).
|
 |
Evaluarea performanței
Acuratețea și alte metrici Click to read
Există diverse metrici care pot fi utilizate pentru măsurarea performanței unui model antrenat. Selectarea metricii depinde de tipul modelului (învățare supervizată, nesupervizată sau prin recompensă; clasificare vs regresie) și de contextul de utilizare. Ne vom concentra pe învățarea supervizată.
➢Cea mai frecvent utilizată măsură de performanță pentru modelele de regresie este MSE.
➢Cea mai des folosită măsură de performanță pentru modelele de clasificare este acuratețea.
➢Cu toate acestea, acestea nu sunt întotdeauna cele mai bune metrici de utilizat.
Clasificatorii binari sunt sisteme de clasificare în care există doar două clase țintă posibile: POZITIV si NEGATIV.
Vom examina diferite valori de performanță pentru acestea și de ce, în anumite circumstanțe, sunt preferabile acurateței.
Să începem cu un instrument utilizat în mod obișnuit pentru a ajuta la înțelegerea performanței unui clasificator binar: matricea de confuzie (vezi slide-ul următor).

Când este indicat să fie utilizată o altă metrică decât acuratețea?
➢Când clasele țintă sunt sever dezechilibrate: de exemplu, dacă 95% sunt valori POZITIVE, și doar 5% sunt NEGATIVE, atunci un clasificator care pur și simplu a clasificat totul ca fiind POZITIV ar avea o precizie uimitoare de 95%. Dar, la ce ar folosi?
➢Este mai important să se identifice corect toate valorile POZITIVE (de exemplu, într-un diagnostic medical, vrem să ne asigurăm că surprindem prezența unei boli, pentru a putea începe tratamentul)? Sau este mai important să evităm estimările fals POZITIVE?
Să luăm în considerare un exemplu „real”: detectarea automată a discursului instigator la ură pe rețelele sociale.
Conform datelor obținute în cadrul proiectului „Barometro dell‘Odio” al Amnesty International Italia (a se vedea prezentarea data4good), discursul instigator la ură reprezintă aproximativ 1% din conținutul politic online. În acest caz, chiar și pentru un sistem de detectare a discursului instigator la ură cu 99% TPR și 1% FPR:
For every 100 comments that it labels as hate speech, we can expect ___ of them to actually be neutral comments.
Lets consider a „real-life“ example: automated hate speech detection on social media.
According to data obtained in Amnesty International Italy‘s „Barometro dell‘Odio“ project (see the data4good slides), hate speech makes up about 1% of online political content. In that case, even for a stellar hate speech detection system with 99% TPR and 1% FPR:
Pentru fiecare 100 de comentarii pe care le etichetează drept discurs instigator la ură, ne putem aștepta ca ___ dintre ele să fie de fapt comentarii neutre.
Nu mă crede pe cuvânt
Următorul slide are o foaie Excel încorporată - vă puteți juca cu numerele.

Bootstrapping și validare încrucișată Click to read
Bootstrapping:
Bootstrapping-ul se bazează pe efectuarea unei eșantionări aleatorii cu înlocuire (adică se ia vaza cu bile colorate, atât de frecvente în textele cu probabilități, încât se trage aleatoriu o minge, se notează culoarea și se aruncă mingea înapoi în vază) pe datele de antrenament. Aceasta înseamnă că aceeași observație poate fi trasă de mai multe ori, în timp ce alte observații pot să nu fie trase deloc.
Acest procedeu statistic este exploatat: eșantioanele sunt extrase din datele de antrenament de câte ori este necesar, până când se obține un nou set de date de antrenament de aceeași dimensiune. Acele observații care nu au fost niciodată trase în această procedură sunt introduse în setul de date de validare. Rezultatele validării sunt folosite pentru a compara diferiți algoritmi.
Validare încrucișată:
Există diferite moduri de a efectua validarea încrucișată, dar ne concentrăm pe validarea încrucișată de n ori și setăm n = 5 pentru simplitate.
Setul de date de antrenament este împărțit, prin eșantionare aleatorie, în 5 subgrupuri de dimensiuni aproximativ egale.
➢La prima trecere, se folosește grupul de date 1 ca date de validare și datele rămase (grupurile 2,3,4,5) sunt date de antrenament.
➢La a doua trecere, al doilea grup de date este pus deoparte pentru validare, iar algoritmul se antrenează pe celelalte grupuri de date (1,3,4,5).
➢Se continuă în acest fel până când toate cele 5 grupuri de date au servit drept date de validare o singură dată.
➢Se folosesc apoi 5 metrici de validare (de exemplu, rata de eroare pentru clasificare, MSE pentru regresie) care pot fi folosite pentru a compara diferiți algoritmi.
➢Odată ce validarea este finalizată și a fost selectat „cel mai bun” model, acesta poate fi reantrenat pe întregul set de date.
Considerații suplimentare Click to read
Privind doar acuratețea modelului uneori nu este suficientă.
Luați în considerare următorul exemplu.
Multe sisteme AI sunt folosite pentru clasificare. Aici, de exemplu, pentru clasificarea imaginilor.
După multe exemple, algoritmul a „învățat”...

După multe exemple, algoritmul a învățat...
It does not detect wolf vs. dog – it detects snow vs. no snow!

Privind doar acuratețea modelului uneori nu este suficient.
Pentru multe aplicații, este, de asemenea, necesar să înțelegem ce șabloane a detectat algoritmul și ce variabile au condus la rezultatul modelului. Transparența și explicabilitatea pot fi caracteristici importante de „calitate”, iar acest lucru poate duce și la alegerea modelului care funcționează „cel mai bine”.
În plus, în fișierul data4good, sunt prezentate alte criterii, cum ar fi corectitudinea și nediscriminarea, care pot fi caracteristici importante atunci când se evaluează performanța unui model.
|
 Redare audio
Redare audio









