DataScience Training
 Play Audio
Play Audio 





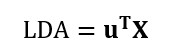
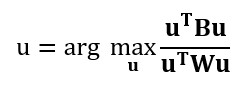



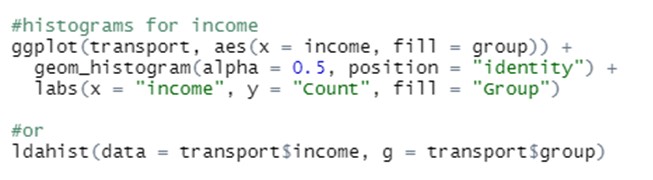
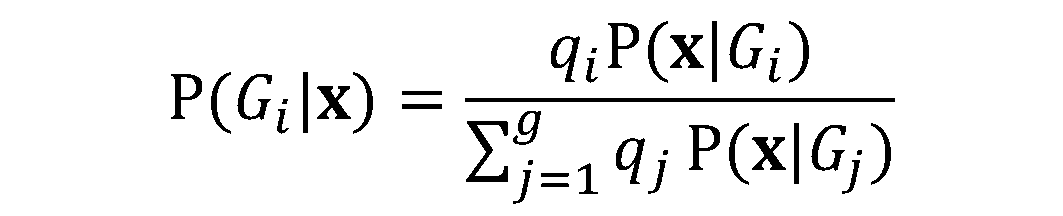
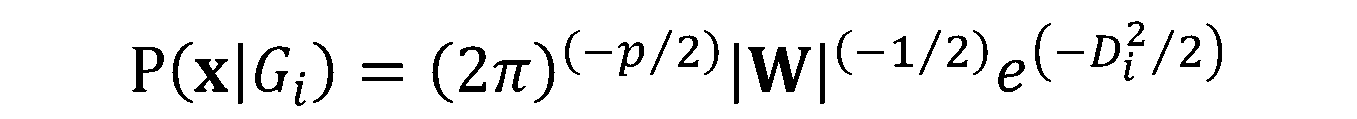




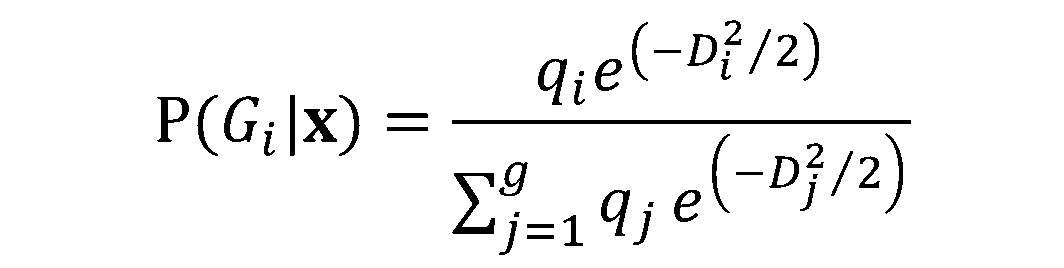


Keywords
discriminant analysis, classification, R, Bayesian analysis
Objectives/goals:The objective of this module is to introduce and explain the basics of Linear Discriminant Analysis (LDA).
At the end of this module you will be able to:
- Identify situations on which LDA can be useful
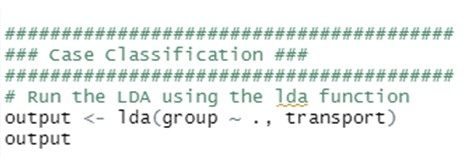
- Calculate LDA functions
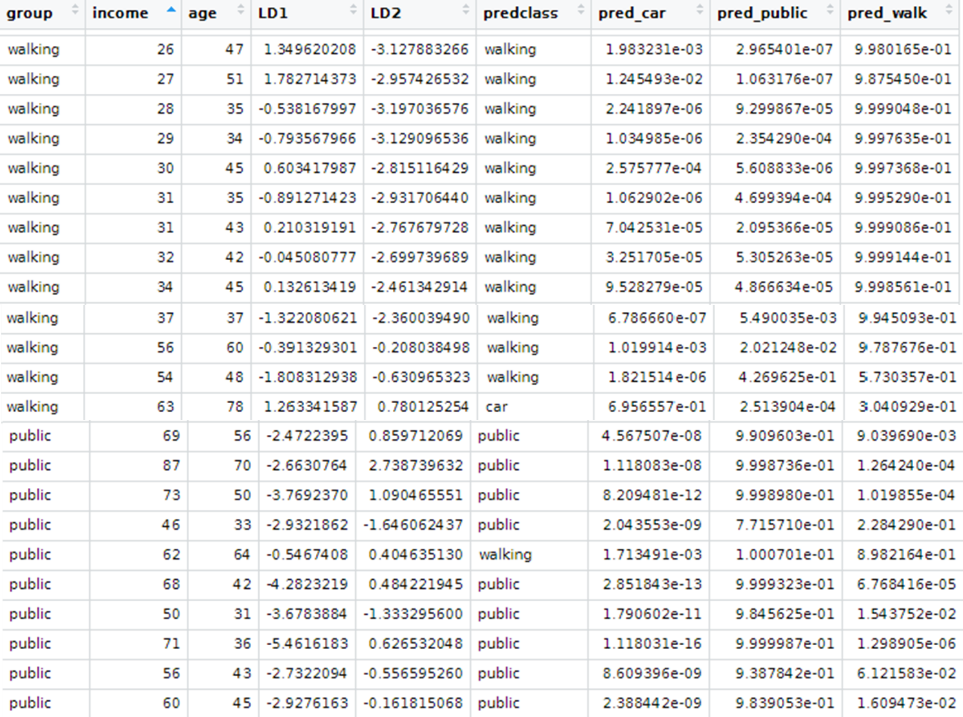
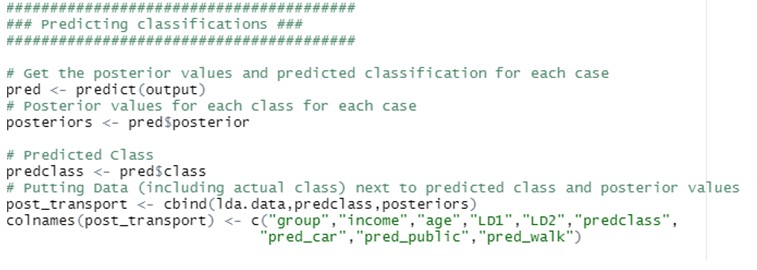
Interpret the results produced by descriptive and predictive LDA
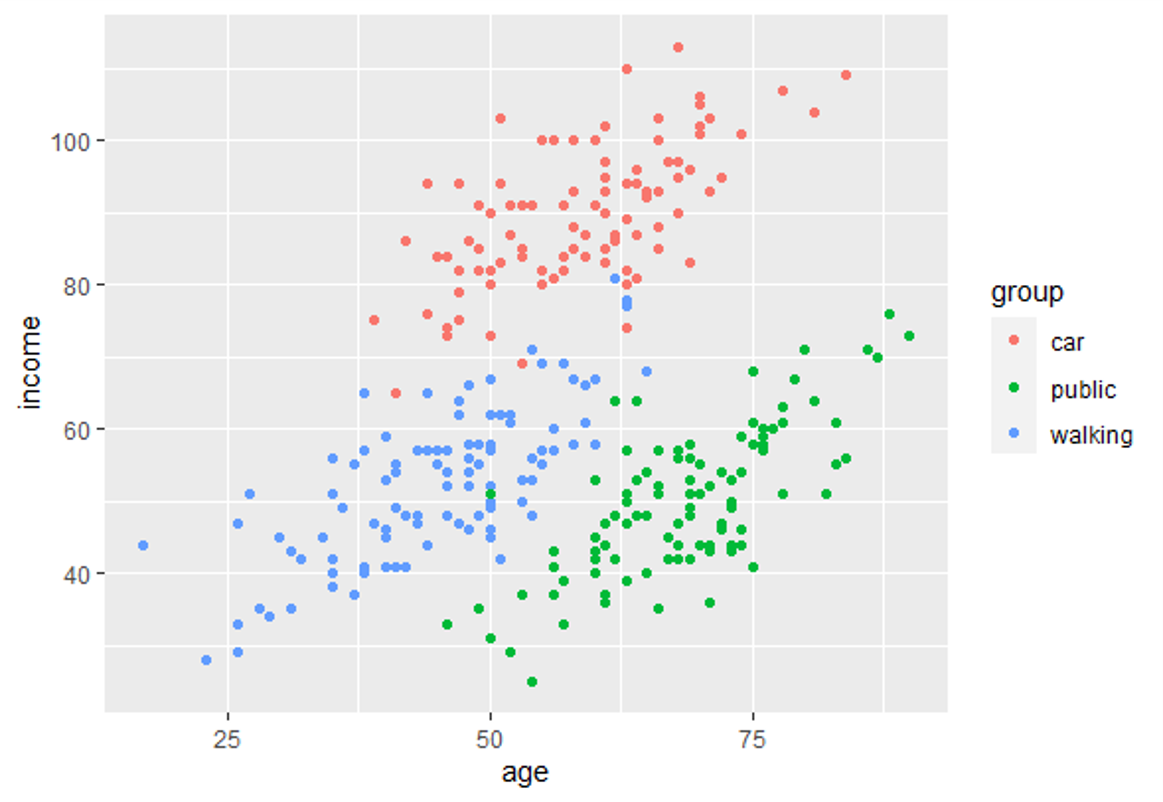
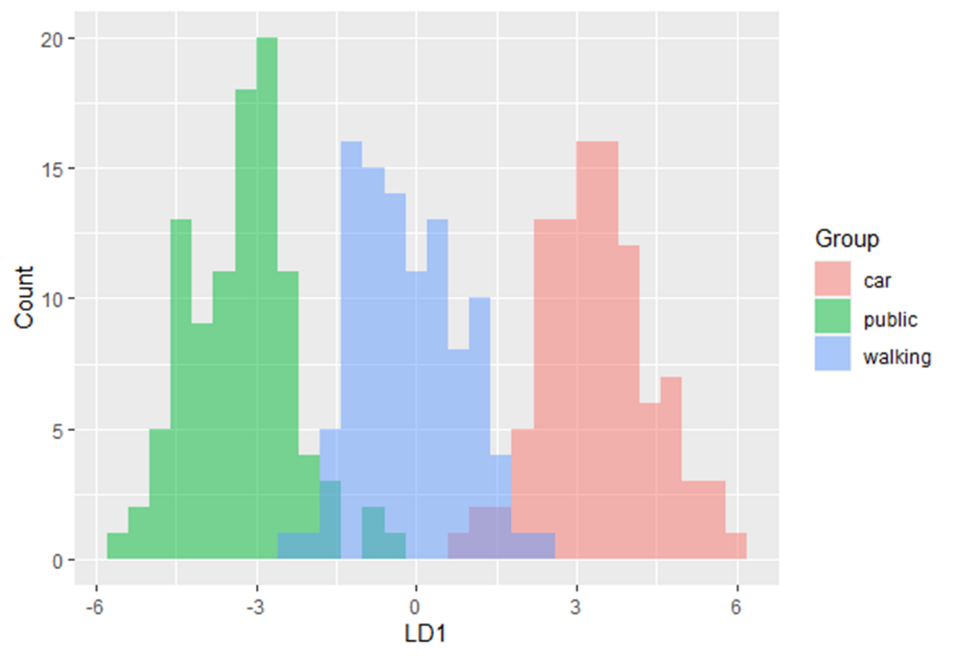
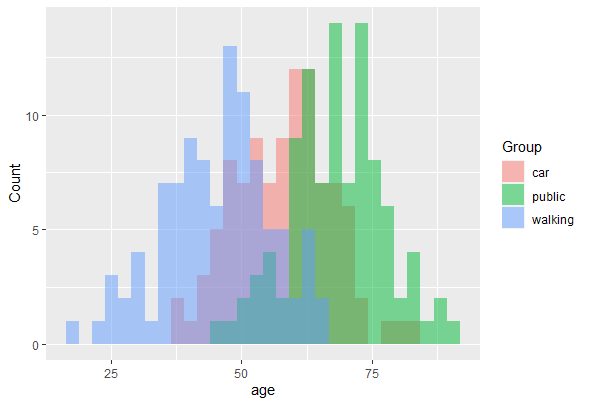
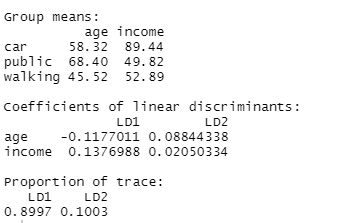
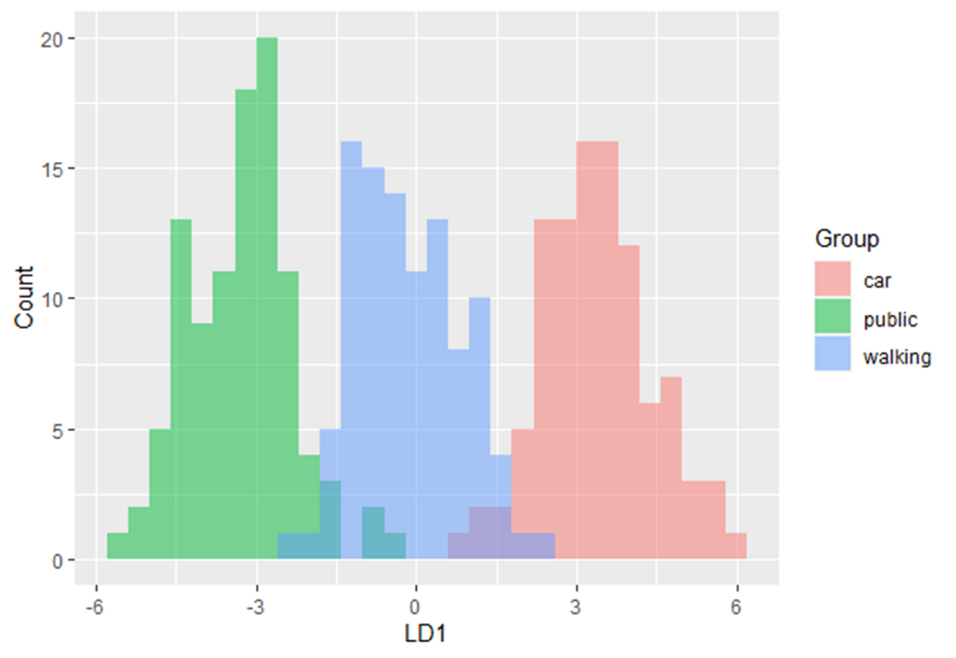
In this training module you will be introduced to the use of Linear Discriminant Analysis (LDA). LDA is as a method for finding linear combinations of variables that best separates observations into groups or classes, and it was originally developed by Fisher (1936).
This method maximizes the ratio of between-class variance to the within-class variance in any particular data set. By doing this, the between-groups variability is maximized, which results in maximal separability.
LDA can be used with purely classification purposes, but also with predictive objectives.
Boedeker, P., & Kearns, N. T. (2019). Linear discriminant analysis for prediction of group membership: A user-friendly primer. Advances in Methods and Practices in Psychological Science, 2, 250-263.
Related training material






